Editor's note: There is always a hazy beauty in taking pictures when it rains, but the water droplets attached to the camera and windows will reduce the visibility of the background and make the photo blurry. In order to remove the water droplets on the photos, researchers at the Institute of Computer Science and Technology of Peking University created an attention generation confrontation network, which worked well. The following is Lunzhi's compilation of the paper.
Photos taken when it rains are blurred because the image content of the area covered by the raindrops is different from that of the area without raindrops. At the same time, the shape of the raindrops is spherical, and the light will become a "fish-eye" effect after refraction, so that the broad scenery is concentrated to a point. . In addition, in most cases, the focus of the camera is on the background, so it will blur the raindrops in the foreground.
In this article, we solved this problem. Given a picture of rain, our goal is to make it clear. The general effect is shown in Figure 1.

figure 1
Our method is completely automatic, which is believed to be helpful for image processing and computer vision applications, especially for similar problems, such as removing stains on photos.
problems at hand
Generally speaking, the problem of removing water droplets is tricky. Because first of all, we don't know the original image of the area covered by rain (this article is based on a single picture to restore, there is no comparison picture). In addition, we have no way of knowing the background information of the occluded area. If the raindrops are larger and more densely distributed, the problem is even more troublesome. In order to solve this problem, we chose to generate a confrontation network.
Rain water is transparent, but due to their special shape and light refraction, a pixel area in the raindrop will be affected by the entire environment, so this raindrop is very different from its background. In certain areas of raindrops, especially the edges and transparent areas, information about the background is usually conveyed. We found that this information can be used in the network through analysis.
We use the following equation to express the blurred image containing raindrops:
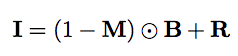
Where I represents the input picture, and M represents the binary mask. In this mask, M(x)=1 means that the pixel x is part of the raindrop, otherwise the pixel is part of the background. B is the background image, and R is the effect of raindrops, representing the phenomenon caused by complex background information and light refraction. ⊙ represents the multiplication of various elements.
Network structure
Figure 2 shows the network structure we proposed:
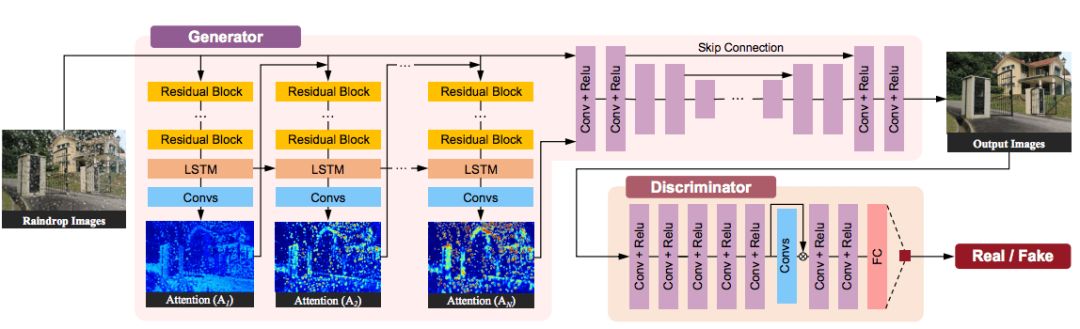
figure 2
Among them, the generated adversarial loss can be expressed as:
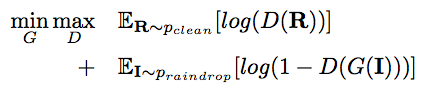
G represents the generation network, D represents the discrimination network, I is a sample image containing raindrops, which will then be input into the generation network, and R is an uncontaminated natural image.
In order to deal with this complex problem, our generative network will first generate an attention map, which is the most important part of the entire network, because it will guide the network to focus on which areas in the next step. The map is generated by a recurrent network containing a deep ResNet, combined with a convolutional LSTM and several standard convolutional layers. We call it an attention recurrent network.
Figure 3 shows how our network generates attention maps during training. It can be seen that our network is not only determining the area of ​​raindrops but also finding out the structure of the surrounding environment.

image 3
The second part of the generation network is an auto-encoder. The purpose of the contextual auto-encoder is to generate a picture without raindrops. The input photo and the attention map will be input into the encoder at the same time. Our deep autoencoder has 16 conv-relu modules, and also adds jump connections to prevent blurry images from being output. The structure of the contextual autoencoder is shown in Figure 4.
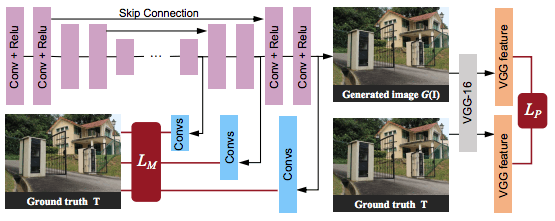
Figure 4
In order to obtain more contextual information, we added a multi-scale loss to the decoder side of the autoencoder. Each loss compares the difference between the output of the convolutional layer and the corresponding standard. The input of the convolutional layer is the characteristic of the decoding layer. In addition to these losses, we also applied a perceptual loss to the final output of the autoencoder to make it closer to the real scene. This final output is also the output of the generating network.
After that, the judgment network will check whether the above output is true. Similar to other methods of removing watermarks and obstacles, our discriminant network will check locally and globally. The only difference is that in our problem, especially in the testing phase, the target area with raindrops is not given. Therefore, the discriminant network cannot focus on local areas because there is no available information. In order to solve this problem, we use the attention map to guide the discriminant network to identify the local area that needs to be processed.
Experimental result
Table 1 shows the comparison between our method and the current Eigen13 and Pix2Pix:
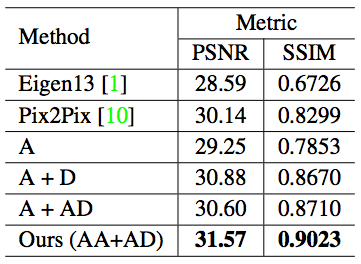
Table 1
Compared with the other two methods, our method has higher PSNR and SSIM scores, which shows that the results generated by our method are closer to the real scene.
At the same time, we also compare the complete GAN structure with the part of our network: A means only autoencoder, no attention map; A+D means no attention autoencoder, and no attention discriminator; A+AD means There is no attention autoencoder, but there is an attention discriminator; AA+AD means there is both an attention autoencoder and an attention discriminator. It can be seen that AA+AD performs better than other methods.
Reflected on the image, as shown in Figure 6 and Figure 7:

Figure 6

Figure 7
Take a closer look:

Test our method with Google Vision API, and the results are as follows:

You can see that Google’s tool can better identify objects in the scene on the processed image.
NINGBO LOUD&CLEAR ELECTRONICS CO.,LIMITED , https://www.loudclearaudio.com