▌1. Understand transfer learning
The goal of Transfer Learning is to use knowledge learned from one environment to help learning tasks in a new environment.
>Theabilityofasystemtorecognizeandapplyknowledgeandskillslearnedinprevioustaskstonoveltasks.
The introduction recommends a generally recognized good [Survey]: ASurveyonTransferLearning, SinnoJialinPan, QiangYang, IEEETrans
http://Docs/2009/tkde_transfer_learning.pdf
In addition, you can also take a look at Dai Wenyuan’s master's degree thesis: Research on Transfer Learning Algorithms Based on Examples and Features
https://download.csdn.net/download/linolzhang/9872535
The author of Survey summarized the knowledge domains related to TransferLearning, it is necessary to understand these terms:
â—Learning-learningtolearn
â—Life-longlearning
â—Knowledge transfer-knowledgetransfer
â—Inductive transfer-inductive transfer
â—Multi-task learning-multi-tasklearning
â—Knowledge consolidation-knowledgeconsolidation
â—Context-sensitive learning-contextsensitivelearning
â—Knowledge-based inductive bias-knowledge-based inductive bias
â—Meta-learning-metalearning
â—Incremental learning-andincremental/cumulativelearning
In addition, the progress and OpenSourceToolkit can refer to:
http://TL/index.html
▌2. Transfer learning classification
According to the similarity of domains and tasks, TransferLearning can be divided as follows:
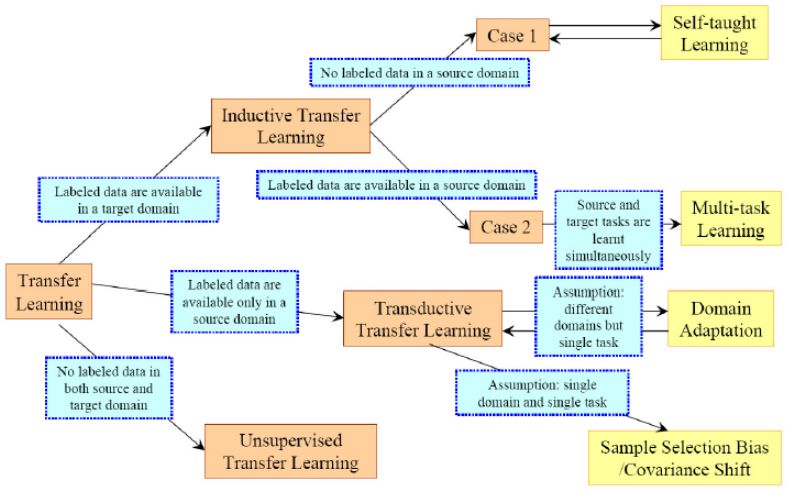
According to the relationship between the source Domain and the current Domain, the relationship between the source Task and the target Task, and the task method, we organize it into the following table in more detail:
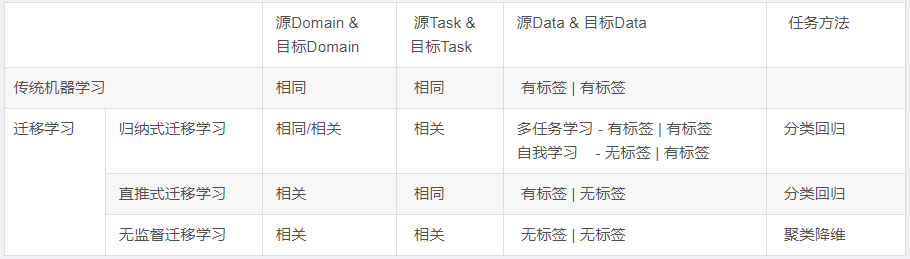
In fact, inductive transfer learning is the most widely used method. From this point of view, transfer learning is more suitable for labeled application domains.
According to the technical method, we divide the transfer learning method into:

Although the transfer learning method has a lot of research work in academics, it is actually not mature in the application field. This is a big proposition in itself, and there is no orthodox system to lead the research direction on the conditions and essence of transfer learning. , And more are groping in experiments.
Migration learning currently faces the following problems:
1. Which situation is suitable for transfer learning? -What
Let me give my own understanding first: classification and regression problems are more suitable for migration learning scenarios, and labeled source data is the best assistance.
2. Which method should I choose? -Which
A simple and effective method is the first choice. The field is developing rapidly, and there is no need to stick to the algorithm itself. Improving the result is the last word.
3. How to avoid negative migration? -How
The goal of transfer learning is to improve the task effect of the target domain. Negative Transfer is a problem faced by many researchers. How to get effective improvements and avoid negative transfer requires everyone to evaluate and weigh.
â–ŒThree. Classic algorithm TrAdaBoost
The TrAdaBoost algorithm is a pioneering work based on sample migration. It was proposed by Dai Wenyuan. It has enough influence to explain it first.
Paper download: BoostingforTransferLearning
http://home.cse.ust.hk/~qyang/Docs/2007/tradaboost.pdf
The basic idea of ​​the algorithm is to filter valid data from the source Domain data, filter out the data that does not match the target Domain, and establish a weight adjustment mechanism through the Boosting method to increase the weight of valid data and reduce the weight of invalid data. The following figure shows the TrAdaBoost algorithm. Schematic diagram (screenshot from Zhuang Fuzhen-Research Progress of Migration Learning):
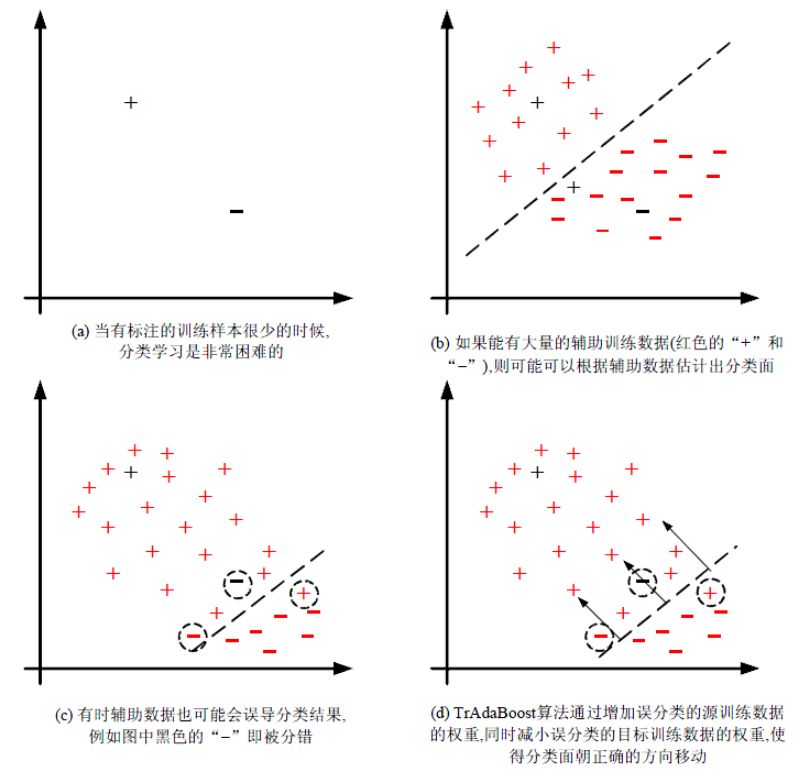
The TrAdaBoost algorithm is relatively simple. It can be summarized in one sentence to find the sample data closest to the target data from the expired data.
Look at the algorithm steps of TrAdaBoost:

What needs to be explained here is the weight update method. For auxiliary samples, the closer the predicted value and the label are, the greater the weight; while for the target data, the opposite is true. The greater the difference between the predicted value and the label, the greater the weight. This strategy is easy to understand. We want to find the sample that is closest to the target data distribution in the auxiliary sample, and at the same time amplify the influence of the target sample Loss, then the ideal result is:
The predicted value of the target sample matches the label as far as possible (don't miss a data that does not match), and the auxiliary sample filters out the most matched (heavier weight) part on the basis of the previous one.
The author gives a theoretical proof later, here are two formulas (to prove the convergence of the algorithm):
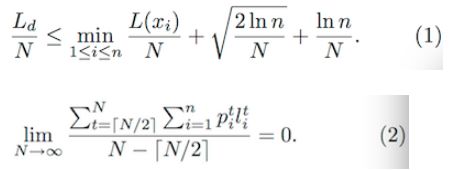
Due to space issues, I won't expand here anymore (same as the author said). If you are interested, you can refer to the original Paper and see the experimental results:
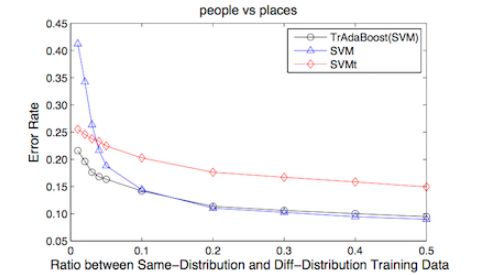
Experiments have found that when the proportion of identically distributed data (target data) is less than 0.1, the algorithm effect is obvious, and when the proportion exceeds 0.1, TrBoost degenerates to the effect of SVM.
This is another obvious conclusion. We believe that when it is greater than 0.1, the current data alone is sufficient to complete the sample training. In this case, the contribution of the auxiliary sample can be ignored.
In addition, when the difference between the target data and the auxiliary data is relatively large, the method does not work, which confirms the original hypothesis, and the proof will not be expanded here.
Finally, give the C code provided by netizens: [download address]
https://download.csdn.net/download/linolzhang/9880438
▌4. Multi-task learning
Multi-Task Learning (MTL) is a machine learning method that learns multiple tasks at the same time. This method has a long history and has nothing to do with deep learning.
If we have to add a link to it and deep learning, we can express it like this:
input1->Hidden1->H1->Out1input1->Out1input2->Hidden2->H2->Out2==>input2->Hidden123->H123->Out2input3->Hidden3->H3->Out3input3->Out3
It is also easier to understand, which is equivalent to merging multiple Task networks and training multiple tasks at the same time. This situation is not uncommon, such as the following two directions:
1) Target detection-compound multitasking
Target detection is a combination of classification problem + regression problem. This is a typical Multi-Task, such as:
Detection=Classification+Location
MaskRCNN=Classification+Location+Segmentation
The detection problem has been described a lot earlier, so I won’t map it here anymore.
2) Feature extraction
Multi-task feature extraction, multiple outputs, this type of problem represents data structuring and feature recognition.
The picture below is the TCDCN (FacialLandmarkDetectionbyDeepMulti-task Learning) published by the Tang Xiaoou Group of the Chinese University of Hong Kong.
Here Multi-Task is simultaneously used for face key point positioning, pose estimation and attribute prediction (such as gender, age, race, smile? Wearing glasses?)

Multi-task learning is suitable for situations like this:
1) There are correlations between multiple tasks, such as pedestrian and vehicle detection. Deep networks can also be understood as having a common network structure;
2) The training data for each independent task is relatively small, and individual training cannot effectively converge;
3) There is correlation information between multiple tasks, which cannot be effectively mined in separate training;
You can take a look at this Tutorial:
~jye02/Software/MALSAR/MTL-SDM12.pdf
You can learn more about the application of multi-task learning, such as secondary classification under classification tasks, face recognition, etc.
High efficient charging speed for Acer laptop, stable current outlet can offer power for the laptop at the same time charge the laptop battery. The best choice for your replacement adapter. The DC connector is 5.5*1.7mm or 3.3*1.0mm. We can meet your specific requirement of the products, like label design. The plug type is US/UK/AU/EU. The material of this product is PC+ABS. All condition of our product is 100% brand new.
Our products built with input/output overvoltage protection, input/output overcurrent protection, over temperature protection, over power protection and short circuit protection. You can send more details of this product, so that we can offer best service to you!
Laptop Adapter For Acer,Charger For Acer,Acer Laptop Adapter ,Ac Adapter For Acer
Shenzhen Waweis Technology Co., Ltd. , https://www.waweis.com