FPGA-based universal CNN acceleration design can greatly shorten the FPGA development cycle, support fast iteration of business deep learning algorithms, provide computing performance comparable to GPU, but have the advantage of delay compared to GPU orders, and build the strongest for business. Real-time AI service capabilities.
WHEN? Deep learning heterogeneous computing statusWith the rapid growth of Internet users and the rapid expansion of data volume, the demand for computing in data centers is also rising rapidly. At the same time, the rise of computationally intensive areas such as artificial intelligence, high-performance data analysis, and financial analysis has far exceeded the power of traditional CPU processors.
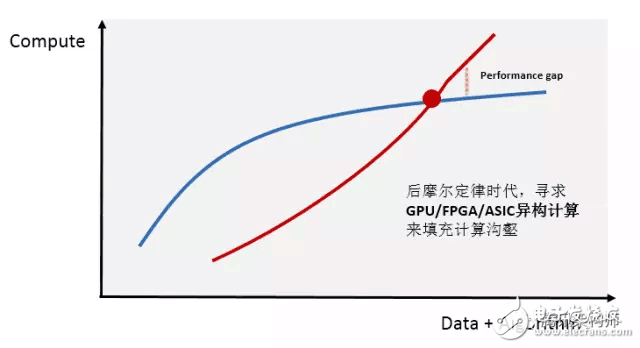
Heterogeneous computing is considered to be the key technology to solve this computing gap at present. Currently, "CPU+GPU" and "CPU+FPGA" are the most heterogeneous computing platforms that the industry pays attention to. They have the computational performance advantages of higher efficiency and lower latency than traditional CPU parallel computing. Faced with such a huge market, a large number of enterprises in the technology industry have invested a large amount of capital and manpower, and the development standards for heterogeneous programming are gradually maturing, while mainstream cloud service providers are actively deploying.

The industry can see that giant companies such as Microsoft have deployed high-volume FPGAs for AI inference acceleration. What are the advantages of FPGAs over other devices?
Flexibility: Programmability Natural Adaptation ML Algorithm in Rapid Evolution
DNN, CNN, LSTM, MLP, reinforcement learning, decision trees, etc.
Arbitrary precision dynamic support
Model compression, sparse network, faster and better network
Performance: Building real-time AI service capabilities
Low latency prediction capability compared to GPU/CPU orders of magnitude
Single watt performance capability compared to GPU/CPU orders of magnitude
Scale
High-speed interconnect IO between boards
Intel CPU-FPGA architecture
At the same time, the short board of FPGA is also very obvious. FPGA uses HDL hardware description language for development, with long development cycle and high entry threshold. Taking separate classic models such as Alexnet and Googlenet as an example, custom-developed accelerated development of a model often takes several months. The business side and the FPGA acceleration team need to balance the algorithm iteration and adapt the FPGA hardware acceleration, which is very painful.
On the one hand, FPGAs need to provide low-latency high-performance services that are competitive with CPU/GPU. On the one hand, FPGA development cycle is required to keep up with the iterative cycle of deep learning algorithms. Based on these two points, we design and develop a universal CNN accelerator. Taking into account the general design of the mainstream model operator, the model acceleration is driven by the compiler to generate instructions, which can support model switching in a short time. At the same time, for the emerging deep learning algorithm, the correlation operator is fast on this common basic version. Development iterations, model acceleration development time has been reduced from the previous months to now one to two weeks.
HOW? Generic CNN FPGA ArchitectureThe overall framework of the general CNN accelerator based on FPGA is as follows. The CNN model trained by Caffe/Tensorflow/Mxnet framework generates the corresponding instructions of the model through a series of optimizations of the compiler. At the same time, the image data and model weight data are pre-processed according to the optimization rules. After processing and compression, it is sent to the FPGA accelerator through PCIe. The FPGA accelerator works in full accordance with the instruction set in the instruction buffer. The accelerator executes the instruction in the complete instruction buffer to complete the calculation acceleration of a picture depth model. Each functional module is relatively independent and is only responsible for each individual module calculation request. The accelerator is separated from the deep learning model, and the data dependencies and pre- and post-execution relationships of each layer are controlled in the instruction set.
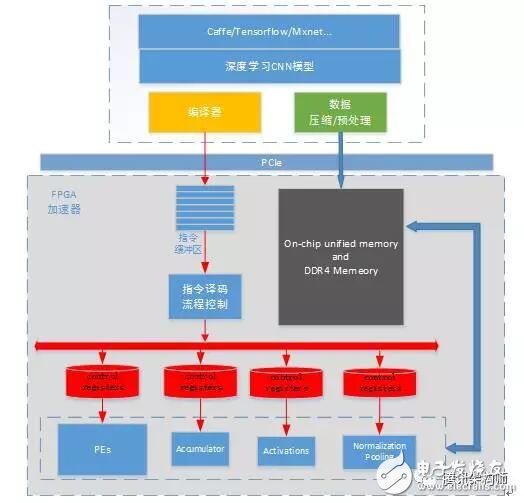
In simple terms, the main job of the compiler is to analyze and optimize the model structure, and then generate an instruction set that the FPGA executes efficiently. The guiding idea of ​​compiler optimization is: higher MAC dsp computational efficiency and less memory access requirements.
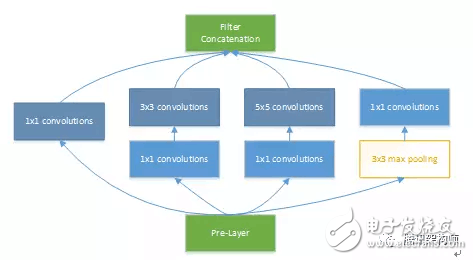
Next, we take the Googlenet V1 model as an example to do a simple analysis of the accelerator design optimization ideas. The IncepTIon v1 network, which combines 1x1, 3x3, 5x5 conv and 3x3 pooling stacks, increases the bandwidth of the network and increases the network's adaptability to scale. The figure below shows the basic structure of IncepTIon in the model.
This section mainly analyzes the flowable and parallelizable calculations in the mining model. Streamlined design can increase the utilization of computing units in the accelerator, and parallelized calculations can utilize as many computational units as possible at the same time.
Regarding the pipeline, the analysis part includes the flow of data from the DDR loading to the SRAM on the FPGA and the calculation of the PE. The optimization of the memory access time overlap; the DSP calculates the calculation control process of the entire column to ensure the improvement of the DSP utilization.
With regard to parallelism, it is necessary to focus on the parallel relationship between PE computing arrays and "post-processing" modules such as activation, pooling, and normalization. How to determine data dependencies and prevent conflicts is the key to design here. In IncepTIon, it can be seen from its network structure that the 1x1 convolution calculation of branch a/b/c and the pooling in branch d can be calculated in parallel, and there is no data dependency between the two. By optimizing here, the calculation of the 3x3 max pooling layer can be completely overlapped.
Model optimizationThere are two main considerations in the design: finding model structure optimization and fixed-point support for dynamic precision adjustment.
Balancing Head Boards of various types including 2bnds,4bnds head boards,etc, which is specially used for balancing and pulling splited conductors in electric power line transmission project, etc. It is made of high strength steel with small volume, light weight, no-damage to conductors. By high quality steel material and good design, this kind of Conductor Head Boards can be durable and long service life. we are a professional Chinese exporter of Balancing Head Board and we are looking forward to your cooperation.
Yangzhou Qianyuan Electric Equipment Manufacturing & Trade Co. Ltd is specialized in manufacturing and trade of electric power line transmission tools. Our main products are Anti-twisting Steel Wire Rope,Stringing Pulley,Hydraulic Crimping Compressors,Engine Powered Winch,Motorised Winch,Wire Grip,Gin Pole,Cable Stand,Mesh Sock Grips,Cable Conveyor,Lever Chain Hoists and so on,which are mainly supplied to power companies,railroad companies and other industry fields.
All our products are certified by China National Institute.To assure the quality, we will do 100% inspection for raw material, production procedure, packing before shipment,
so we do have the confidence to supply customers with high-quality and high-efficiency products.
"Customer satisfaction" is our marketing purposes,so we have extensive experience in professional sales force,and strongly good pre-sale, after-sale service to clients. We can completely meet with customers' requirements and cooperate with each other perfectly to win the market.Sincerely welcome customers and friends throughout the world to our company,We strive hard to provide customer with high quality products and best service.
head boards, balancing head boards, balancing running boards
Yangzhou Qianyuan Electric Equipment Manufacturing & Trade Co.Ltd , https://www.qypowerline.com