When talking about the laws of the new economy, John Chambers, president of Cisco, said that modern competition has "not a big fish to eat small fish, but to eat slowly." In modern competition, efficiency has a decisive role. .
Engineers who do embedded development know that once the product needs to be mass-produced, mass-produced burners are essential. In the debugging phase, engineers can use the serial port to download to achieve code burning. If the serial port is used for production, the factory will never allow it because the efficiency is too low.
The function of the programmer is mainly to operate the non-volatile memory (the internal Flash of the MCU is also a variety of non-volatile memories). These memories usually require erasure, programming, and verification. These basic operations and some control setting operations are the main contents of the programming.
Under normal circumstances, these operations are performed in sequence, first erase, after the erase is completed, the memory is power-up programming, after the programming is completed, the programmed part is verified and compared. These steps are interlocking, step by step, and the serial processing efficiency is very low. Just as one person is busy with one thing, then two people and three people come together, and the efficiency is immediately increased by three times.
The way to achieve step by step is the practice of many cottage burners on the market, which is inefficient.

Figure 1 cottage burner
Professional burner manufacturers not only improve the working frequency when burning, but also try to improve the parallelism between commands to maximize efficiency.
With a little thought, you will find that the programmer is executed in such a sequence during the programming process: taking command data from the host computer → command parsing → execution. This process is a cyclic execution, the corresponding operations are fetch, decode and execute, as explained below:
Fetch----Remove the command from the command FIFO.
Decode----According to the instruction, generate the corresponding control signal.
Execute----Execute erase, program or verify operation, or set related parameters.
If the pipeline technology is not used, the space-time diagram is shown in Figure 2.
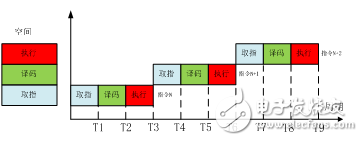
Figure 2 no pipeline time-space diagram
As can be seen from Figure 2, each command must be fetched, decoded, and executed before the next command can be executed, which seriously affects the efficiency of the system. The most deadly thing is that fetching, decoding, and execution can't work at the same time. It can only be decoded after the fetch is completed, and can be executed after decoding.
As a result, the burner has changed and adopted the "pipeline" technology. According to the operation steps of the programmer, the workflow can be divided into three parts: instruction fetching, decoding and execution, each part responsible for its own work. This not only refines the entire workflow, but also enables the three parts to work at the same time, thereby increasing the degree of parallelism and thus improving work efficiency. In the FPGA hardware implementation, these three parts correspond to three circuits, and a register group is inserted between them to form a three-stage pipeline, as shown in Figure 3. Thus, at each clock cycle, the fetch, decode, and execute portions simultaneously use the data transferred from the previous stage, and pass the result to the register for use in the next stage of the circuit in the next cycle. In this process, the register acts as a temporary result.

Figure 3 schematic diagram of the pipeline circuit
The space-time diagram using pipeline technology is shown in Figure 4.
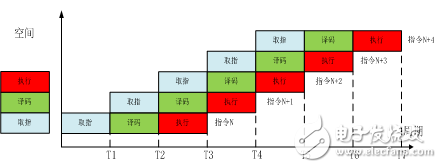
Figure 4 Pipeline time and space diagram
As can be seen from Figure 4, the related command executions overlap in time, that is, the three commands work simultaneously (after the first delay)! For example, at time T4, the instruction N+3 is taking the value, the instruction N+2 is decoding, and the instruction N+1 is executing. It is worth noting that at some point, although they work at the same time, they are not operating the same instruction. In addition, in each cycle, there is a command "execution", which means that one cycle produces a result, and no pipeline technology requires 3 cycles to have a result, compared to a threefold increase in work efficiency. The good news is that the pipeline technology will increase the frequency cap.
In the FPGA design, it is necessary to estimate the value, the decoding and the delay of the lower three parts, and try to make the delay between them equal or close, in order to take advantage of the pipeline. In addition, in theory, the more the number of pipeline stages, the faster the operating frequency and the higher the efficiency.
Tinned Copper Clad Aluminum TCCA
Copper Clad Aluminum Tinned Wire,Tinned Copper Clad Aluminum Audio Cable,Tinned Copper Clad Aluminum Alloy Wire ,Copper Clad Aluminum Tin Plating
changzhou yuzisenhan electronic co.,ltd , https://www.ccs-yzsh.com