Recently, research has shown that the method of generating English Wikipedia articles can be summarized as a multi-document summary of the source document. We use extractive summarization to roughly identify the saliency information and a neural abstraction model to generate the essay. For the abstract model, we introduce a decoding-only architecture that can handle very long sequences expansively, much longer than the typical encoder-decoder architecture used in sequence conversion. Our research shows that this model can generate smooth, coherent multi-sentence paragraphs, and even entire Wikipedia articles. When a reference is given, the results show that it can extract relevant factual information from information such as complexity, ROUGE scores, and human evaluations.
Sequence-sequence frameworks have proven successful in natural language sequence conversion tasks such as machine translation. Recently, neural technology has been applied to the processing of single-document, abstract (interpretive) text summaries of news articles. In previous studies, the input range of the supervisory model included the first sentence of the article to the entire text, and it was to be end-to-end trained to predict the reference summary. Because language understanding is a prerequisite for generating a smooth summary, doing this end-to-end operation requires a large number of parallel article-summary pairs.
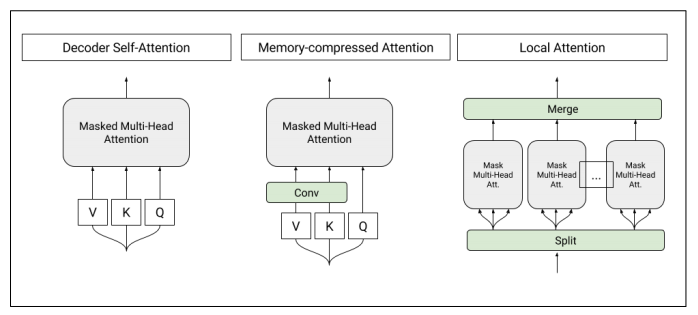
Figure 1: Architecture of self-attention layers used in the T-DMCA model. Each attention layer takes a sequence of characters as input and produces a sequence of similar length as an output. Left: Original self-attention used in the converter decoder. Medium: Memory-compressed attentionyers, reducing the number of keys/values. Right: Partial attention to segment the sequence into a single smaller subsequence. These subsequences are then combined together to obtain the final output sequence.
Instead, we considered the task of multiple document summaries, where the input is a collection of related documents and its summary is refined. Previous research efforts have focused on extractive summaries, choosing sentences or phrases from input to form abstracts instead of generating new ones. The application of abstract neural methods has certain limitations. One possible reason is the lack of large labeled data sets.
In this study, we consider English Wikipedia as a multi-document summary supervised machine learning task in which the input consists of a collection of Wikipedia themes (article titles) and non-Wikipedia references, targeting Wikipedia. Article text. For the first time, we attempted to abstractly generate the first part or citation of a Wikipedia article based on reference text. In addition to running a powerful baseline model on the task, we also modified the Transformer architecture (proposed by Vaswani et al. in 2017) to include only one decoder, in the case of longer input sequences, and loops. The neural network (RNN) and the Transformer encoder-decoder model have better phenotypic performance. Finally, the results of the study show that our modeling improvements allow us to generate complete Wikipedia articles.
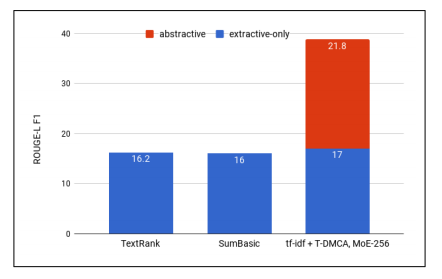
Figure 2: ROUGE-L F1 for various extraction methods, the contribution of the abstract model is expressed as the d tf-idf-T-DMCA model for optimal combination
Other data sets for neural abstractions
The Neural abstractive summarization was proposed by Rush et al. (in 2015), in which they used the English Gigaword corpus (reported in 2003 by Graff and Cieri), including news reports from multiple publishers. Generate models for training. However, this task is more like the interpretation of a sentence than a summary, because only the first sentence of the article is used to predict the title and another sentence. In ROUGE (an automatic metric that is often used for abstracts) and human assessment (as proposed by Chopra et al. in 2016), an encoder-decoder model (seq2seq) based on RNN's attention is used. This task has good performance.
In 2016, Nallapati et al. proposed an abstract summary data set by modifying the Daily Mail and CNN's question data sets with news stories with story highlights. This task is more difficult than title generation because the information used in the highlights may come from multiple parts of the article, not just the first sentence. One disadvantage of the data set is that it has a smaller number of parallel samples (310k vs 3.8M) for learning. The standard-focused seq2seq model does not perform well, and a number of techniques are used to improve performance. Another downside is that it is unclear what the criteria for making a story highlight are, and it is clear that there are significant differences in the style of the two news publishers.
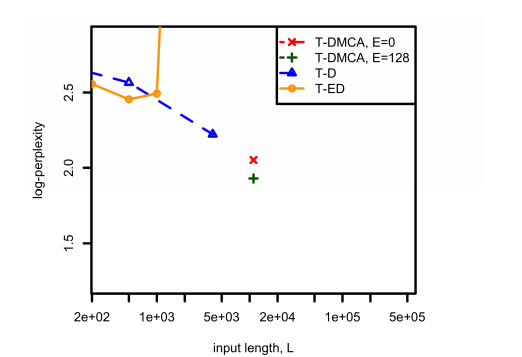
Figure 3: Comparison of the complexity and the relationship between L in the tf-idf extraction problem on a combined corpus for different model architectures. For T-DMCA, E represents the size of the expert-of-experts.
In our research, we also trained on neural abstract models, but in Wikipedia's multi-documentation mechanism. As you can see from Table 1, the input and output text is usually much larger and has significant differences depending on the article. In general, abstracts (the main content of Wikipedia) tend to be multiple sentences, sometimes multiple paragraphs, and, as advocated in the Wikipedia style manual, are written in a fairly uniform style. However, the input document may contain any style of document from any source.

Table 1: Order-level input/output size and unigrams callbacks for summary datasets
We also give the output callback score for the given input of ROUGE-1 in Table 1, which is the ratio of unigrams/words that appear simultaneously in the input and output. Higher scores correspond to a data set that is easier to perform for extractive digest processing. In particular, if the output is fully embedded somewhere in the input (such as a wiki copy), the score will be 100. Compared to the scores for other summary datasets of 76.1 and 78.7, and our score of 59.2, our method is the least suitable for pure extraction.
Tasks involving Wikipedia
In fact, there are many research efforts that use Wikipedia for machine learning tasks, including question answering, information extraction, and text generation in structured data.
The closest research work involving Wikipedia to us is Sauper and Barzilay (in 2009), where the article was generated using a learning template from a reference document (rather than an abstraction like in our case). . Wikipedia articles are limited to two categories, and we use all article types. The reference documentation was obtained from a search engine, where the Wikipedia theme used for the query is quite similar to our search engine reference. However, we will also display the results of the documentation in the "References" section of the Wikipedia article.

Figure 4: The prediction results of the same sample in different models are shown.
In Figure 4, we present the predictions from three different models (using tf-idf extraction and combined corpus) and the basic facts of Wikipedia. As the complexity decreases, we see that the output of the model is improved in terms of fluency, fact accuracy, and narrative complexity. In particular, the T-DMCA model provides an alternative to the Wikipedia version and is more concise, while mentioning key facts such as where the law firm is located, when, how it was formed, and the rise of the firm. And decline.

Figure 5: Translation from Transformer-ED, L = 500
In the manual inspection of the model output, we noticed an unexpected side effect: the model tried to translate the English name into multiple languages, for example, to translate Rohit Viswanath into Hindi (see Figure 5). Although we did not systematically evaluate translations, we found that they were often correct and did not find them in the Wikipedia article itself. We also confirm that, in general, translation is not just copied from a source such as a sample sample, where the target language is incorrect (for example, a translation from English to Ukrainian).
We have shown that Wikipedia's generation can be seen as a multi-document summary problem with a large, parallel data set and a two-stage extraction-abstract framework to implement it. The crude extraction method used in the first stage seems to have a significant impact on the final performance, indicating that further research will yield results. In the abstraction phase, we introduced a new conversion model with only decoder sequences that can handle very long input-output samples. The model's performance over long sequences is significantly better than the traditional encoder-decoder architecture, allowing us to generate coherent and informative Wikipedia articles based on many references.
Electric Portable Juice Blender
Electric Portable Juice Blender,Portable Juicer Blenders,Usb Rechargeable Juicer Blender,Rechargeable Juicer Blender
Shandong Sangle Group Co.,Ltd. , https://www.sangle-group.com