Communicate with the machine and let it understand what you are talking about. Speech recognition technology has turned the once-dream of mankind into reality. Speech recognition is like a "machine's auditory system," which allows a machine to transform a speech signal into a corresponding text or command by recognizing and understanding.
At the Bell Institute in 1952, Davis et al. developed the world's first experimental system that could recognize 10 English digital pronunciations. In 1960, Denes et al. of the United Kingdom developed the first computer speech recognition system.
Large-scale speech recognition research began in the 1970s and made substantial progress in the identification of small vocabulary and isolated words. After the 1980s, the focus of speech recognition research has gradually shifted to large vocabulary and non-specific continuous speech recognition.
At the same time, speech recognition has undergone major changes in research ideas. The traditional technical ideas based on standard template matching have turned to technical ideas based on statistical models. In addition, experts in the industry have once again proposed a technical idea to introduce neural network technology into speech recognition.
After the 1990s, there was no major breakthrough in the system framework for speech recognition. However, great progress has been made in the application and productization of speech recognition technology. For example, DARPA is a program funded by the US Department of Defense's Vision Research Program in the 1970s to support the research and development of language understanding systems. In the 1990s, the DARPA program was still in progress, and its research focus had shifted to the natural language processing part of the identification device, and the identification task was set to “air travel information retrievalâ€.
China's speech recognition research began in 1958, and the Chinese Academy of Sciences Institute of Acoustics used the electronic tube circuit to identify 10 vowels. Due to the limitations of the conditions at the time, China's speech recognition research work has been in a slow development stage. Until 1973, the Institute of Acoustics of the Chinese Academy of Sciences began computer speech recognition.
Since the 1980s, with the gradual popularization and application of computer application technology in China and the further development of digital signal technology, many domestic units have the basic conditions for researching speech technology. At the same time, international speech recognition technology has become a research hotspot after years of silence. In this form, many domestic units have invested in this research work.
In 1986, speech recognition was listed as an important part of the research of intelligent computer systems. With the support of the “863†program, China began to organize research on speech recognition technology and decided to hold a special session on speech recognition every two years. Since then, China's speech recognition technology has entered a new stage of development.
Since 2009, with the development of deep learning research in the field of machine learning and the accumulation of big data corpus, speech recognition technology has developed by leaps and bounds.
The deep learning of machine learning domain is introduced into the speech recognition acoustic model training, and the multi-layer neural network with RBM pre-training is used to improve the accuracy of the acoustic model. In this regard, Microsoft researchers took the lead in making breakthroughs. After using the Deep Neural Network Model (DNN), the speech recognition error rate was reduced by 30%, which is the fastest progress in speech recognition technology in the past 20 years.
Around 2009, most mainstream speech recognition decoders have adopted a finite state machine (WFST)-based decoding network, which can integrate language models, dictionaries and acoustic shared sounds into a large decoding network, improving decoding. The speed provides the basis for real-time application of speech recognition.
With the rapid development of the Internet and the popularization of mobile terminals such as mobile phones, a large number of text or speech corpora can be obtained from multiple channels, which provides abundant resources for the training of language models and acoustic models in speech recognition. It is possible to build a universal large-scale language model and acoustic model.
In speech recognition, the matching and richness of training data is one of the most important factors to promote the performance improvement of the system. However, the annotation and analysis of corpus requires long-term accumulation and precipitation. With the advent of the era of big data, large-scale corpus resources Accumulation will refer to strategic heights.
Nowadays, the application of speech recognition on mobile terminals is the hottest. Voice dialogue robots, voice assistants and interactive tools are emerging one after another. Many Internet companies have invested in human resources, material resources and financial resources to carry out research and application in this field. The purpose is to interact through voice. The new and convenient model quickly captures the customer base. (Yakuta finishing) Related products siri
The Siri technology is derived from the CALO program announced by the US Department of Defense's Advanced Research and Planning Agency: a digital assistant that allows the military to streamline some of its cumbersome tasks, with learning, organization, and cognitive capabilities, and its civilian version of the software Siri virtual individual assistant Manager.
Founded in 2007, Siri was originally based on text chat services. Later, through collaboration with voice recognition vendor Nuance, Siri implemented voice recognition. In 2010, Siri was acquired by Apple for $200 million.
Siri became a voice control feature that Apple applied on its iPhone and iPad Air. Siri can transform the iPhone and iPad Air into an intelligent robot. Siri supports natural language input, and can call the system's own weather forecast, schedule, search data and other applications, as well as continuously learn new sounds and intonation, providing a conversational response.
Google Now
Google Now is an application launched by Google along with Android 4.1 system. It can understand users' various habits and ongoing actions, and use the information they know to provide relevant information to users.
On March 24 this year, Google announced that Google Now voice service officially landed on the Windows and Mac desktop Chrome browser.
Google Now’s app makes it easier for users to receive emails, and when you receive a new message, it will automatically pop up for you to view. Google Now also offers walking and driving mileage recording, a pedometer feature that counts the user’s monthly mileage, including walking and cycling, through the sensors of the Android device.
In addition, Google Now has added a number of travel and entertainment features, including: car rental, concert tickets and commuter sharing cards; public transportation and TV program cards are improved, these cards can now listen to music and program information; Users can set search alerts for the launch of new media shows, as well as receive real-time NCAA (American University Sports Association) football scores.
Baidu voice
Baidu voice generally refers to Baidu voice search. It is a voice-based search service provided by Baidu for the majority of Internet users. Users can use a variety of clients to initiate voice search. The server side performs voice recognition based on the voice request sent by the user. Feedback the search results to the user.
Baidu voice search not only provides general universal voice search service, but also features search service for map users. More personalized search and recognition services will follow.
At present, Baidu voice search uses mobile client as the main platform, embedded in other products of Baidu, such as Pocket Baidu, Baidu mobile map, etc. Users can experience voice search while using these client products, and support all mainstream mobile phone operations. system.
Microsoft Cortana
Cortana is a virtual voice assistant under the Windows Phone platform. It is voiced by Corna's seiyuu Jen Taylor in the game Halo. The Cortana Chinese version is also known as "Microsoft Xiaona".
Microsoft's description of Cortana is "a personal assistant on your mobile phone, providing you with more help in setting calendar items, suggestions, processes, etc.", it can interact with you, and simulate people's speech and thinking as much as possible. Ways to communicate with you. In addition, the round icon button will be adjusted according to the theme of your phone. If you set a green theme, then Cortana is a green icon.
In addition, you can call out Cortana by starting the screen or the search button on the device. Cortana uses a question-and-answer approach that only displays enough information when you consult it.
Speech recognition technology is difficultSpeech recognition becomes the focus of competition
It is reported that global artificial intelligence companies specialize in deep learning direction, and more than 70% of the 200 companies in China's artificial intelligence direction focus on image or speech recognition. Which companies in the world are in the process of voice recognition? What is their development situation?
In fact, before the invention of the computer, the idea of ​​automatic speech recognition has been put on the agenda, and the early vocoder can be regarded as the prototype of speech recognition and synthesis. The earliest computer-based speech recognition system was the Audrey speech recognition system developed by AT&T Bell Labs, which recognizes 10 English digits. By the end of the 1950s, Denes of the Colledge of London had added grammatical probabilities to speech recognition.
In the 1960s, artificial neural networks were introduced into speech recognition. Two major breakthroughs in this era were linear predictive coding Linear PredicTIve Coding (LPC) and dynamic time-regulating Dynamic TIme Warp technology. The most significant breakthrough in speech recognition technology is the application of the hidden Markov model Hidden Markov Model. From Baum, the related mathematical reasoning is proposed. After Rabiner et al., Kai-fu Lee of Carnegie Mellon University finally realized the first large vocabulary speech recognition system Sphinx based on hidden Markov model.
Apple Siri
Many people know that speech recognition may also be attributed to Apple's famous voice assistant Siri. In 2011, Apple integrated voice recognition technology into the iPhone 4S and released the Siri voice assistant. However, Siri is not a technology developed by Apple, but acquired the technology acquired by Siri Inc., which was founded in 2007. After the release of the iPhone 4s, Siri's experience was not ideal and was squandered. Therefore, in 2013, Apple acquired Novauris Technologies. Novauris is a speech recognition technology that recognizes the entire phrase. Instead of simply recognizing a single phrase, the technique attempts to use more than 245 million phrases to aid in understanding the context, which further simplifies Siri's functionality.
However, Siri has not been perfected by the acquisition of Novauris. In 2016, Apple acquired the artificial intelligence software developed to help the computer and users to have a more natural dialogue with British voice technology startup VocalIQ. Subsequently, Apple also acquired EmoTIent, an AI technology company in San Diego, USA, to receive facial expression analysis and emotion recognition technology. It is reported that the emotional engine developed by EmoTIent can read people's facial expressions and predict their emotional state.
Google Google Now
Similar to Apple Siri, Google's Google Now is also well known. However, compared to Apple's Google in the field of speech recognition, the action is slightly slow. In 2011, Google acquired the voice communication company SayNow and the voice synthesis company Phonetic Arts. SayNow can integrate voice communications, peer-to-peer conversations, and group calls with applications such as Facebook, Twitter, MySpace, Android, and iPhone, and Phonetic Arts can turn recorded voice conversations into voice libraries and then combine them. Come together to create a very realistic vocal dialogue that sounds like it.
Google Now made its debut at the Google I/O Developers Conference in 2012.
In 2013, Google acquired Wavii, a newsreading application developer, for more than $30 million. Wavii specializes in "natural language processing" technology, which can scan news on the Internet and give a summary and link directly. Later, Google acquired a number of patents related to speech recognition by SR Tech Group. These technologies and patents Google were also quickly applied to the market. For example, YouTube has provided automatic voice transcription support for titles, Google Glass uses voice control technology, and Android also Integrating speech recognition technology and so on, Google Now has a complete speech recognition engine.
Google may have invested in China's door-to-door question in 2015 due to strategic layout considerations. This is a voice-based company. Recently, it also released a smart watch, and there are also domestic famous acoustic device manufacturers. Acoustic background.
Microsoft Cortana Xiaobing
The most eye-catching feature of Microsoft speech recognition is Cortana and Xiao Bing. Cortana is Microsoft's attempt in the field of machine learning and artificial intelligence. Cortana can record user behavior and usage habits, use cloud computing, search engines and "unstructured data" analysis to read and learn images and videos including mobile phones. Data such as e-mails understand the semantics and context of users, thus realizing human-computer interaction.
Microsoft Xiaobing is an artificial intelligence robot released by Microsoft Research Asia in 2014. In addition to intelligent dialogue, Microsoft Xiaobing also has practical skills such as group reminders, encyclopedias, weather, constellations, jokes, traffic guides, and restaurant reviews.
In addition to Cortana and Microsoft Xiaobing, Skype Translator provides real-time translation services for users in English, Spanish, Chinese, and Italian.
Amazon
Amazon's voice technology started in 2011 with the acquisition of the voice recognition company Yap, which was founded in 2006 to provide voice-converted text services. In 2012, Amazon acquired the voice technology company Evi, and continued to strengthen the application of speech recognition in product search. Evi also applied Nuance's speech recognition technology. In 2013, Amazon continued to acquire Ivona Software, a Polish company that specializes in text-to-speech, and its technology has been applied to Kindle Fire's text-to-speech capabilities, voice commands and Explore by Touch applications. Amazon Smart Speaker Echo This technology is also utilized.
Facebook acquired the entrepreneurial speech recognition company Mobile Technologies in 2013. Its product Jibbigo allows users to choose between 25 languages, use one of the languages ​​for voice clip recording or text input, and then display the translation on the screen, while The selected language is read out loud. This technology makes Jibbigo a popular tool for traveling abroad, a good substitute for the common language manual.
After that, Facebook continued to acquire Wit.ai, a voice interactive solution service provider. Wit.ai's solution allows users to control mobile applications, wearables and robots directly, as well as virtually any smart device. Facebook hopes to apply this technology to targeted advertising, combining technology with its own business model.
Traditional voice recognition industry aristocrat Nuance
In addition to the development of speech recognition by the well-known technology giants introduced above, the traditional voice recognition industry aristocrat Nuance is also worth knowing. Nuance once dominated the voice field. More than 80% of the world's voice recognition has used Nuance recognition engine technology. Its voice products can support more than 50 languages, and have more than 2 billion users worldwide, almost monopolizing the financial and telecommunications industries. . Nuance is still the world's largest voice technology company, with the world's most patented voice technology. Apple Voice Assistant Siri, Samsung Voice Assistant S-Voice, automatic call centers of major airlines and top banks, all started with their speech recognition engine technology.
However, because Nuance is a bit too arrogant, Nuance is not as good as it used to be.
Other voice recognition companies abroad
In 2013, Intel acquired Spanish voice recognition technology company Indisys. In the same year, Yahoo acquired the natural language processing technology startup SkyPhrase. Comcast, the largest cable company in the United States, has also begun to launch its own voice recognition interactive system. Comcast hopes to use voice recognition technology to give users more freedom to control the TV through voice and to do things that the remote can't do.
Domestic speech recognition vendor
Keda News
Keda Xunfei was established at the end of 1999. It relied on the voice processing technology of the University of Science and Technology and the support of the state, and soon got on the right track. Keda Xunfei was listed in 2008 and its current market value is close to 50 billion. According to the data survey of the Voice Industry Alliance in 2014, HKUST has occupied more than 60% market share and is definitely the leading domestic voice technology company.
When it comes to HKUST, everyone may think of speech recognition, but in fact, its biggest source of income is education. Especially in 2013, many voice evaluation companies, including Qiming Technology, were acquired, which formed the education market. Monopoly, after a series of acquisitions, the current oral assessment in all provinces is based on the engine of the University of Science and Technology. Because it occupies the commanding heights of the exam, all schools and parents are willing to pay for it.
Baidu voice
Baidu voice was established as a strategic direction very early. In 2010, it cooperated with the Institute of Acoustics of the Chinese Academy of Sciences to develop speech recognition technology, but the market development was relatively slow. Until 2014, Baidu reorganized its strategy and invited Wu Enda, the master of artificial intelligence, to formally form a voice team, specializing in voice-related technology. Thanks to Baidu’s strong financial support, it has so far gained a lot. With nearly 13% market share, its technical strength can be compared with Keda Xunfei, which has accumulated more than ten years of technology and experience.
Jietong and Xinli
Jietong Huasheng relied on Tsinghua technology. At the beginning of its establishment, Mr. Lu Shinan, who invited the Institute of Acoustics of the Chinese Academy of Sciences, joined the committee and laid the foundation for speech synthesis. Zhongke Xinli relies entirely on the Institute of Acoustics of the Chinese Academy of Sciences. Its initial technical strength is extremely strong. It not only cultivates a large number of talents for the domestic speech recognition industry, but also plays a vital role in the industry, especially in the military industry.
These talents cultivated by the Institute of Acoustics of the Chinese Academy of Sciences are extremely important for the development of the domestic speech recognition industry. They are called the Acoustics Department, but compared to the market, the two companies have fallen behind a large distance from the University of Science and Technology. Due to the industry market background, Zhongke Xinli is basically no longer involved in the market operation, and Jietong Huasheng has recently been pushed to the forefront by the fraud of Nanda’s “Jiaojiao†robot, which is really a very negative impact. .
Spirson
Around the year of 2009, DNN was used in the field of speech recognition. The speech recognition rate has been greatly improved, and the recognition rate has exceeded 90%, reaching commercial standards. This has greatly promoted the development of speech recognition. In the past few years, many speech recognitions have been established. Related startups.
Spirit was founded in 2007. Most of its founders are from the Cambridge team. Its technology has a certain foreign foundation. At that time, the company mainly focused on voice evaluation, which is education. However, after years of development, although it has some markets, it is at the University of Science and Technology. In the case of Xunfei holding the test high ground, it is difficult to get a breakthrough.
So in 2014, Si Bi Chi decided to split the department responsible for the education industry and sold it to NetDragon for 90 million yuan. He focused his energy on intelligent hardware and mobile Internet. Recently, he concentrated on car voice. The assistant, launched the "radish", the market response is very general.
Yunzhisheng
With the propaganda momentum of Apple Siri in 2011, Yunzhisheng was established in 2012. The team of Yunzhisheng is mainly from the Shanda Research Institute. Coincidentally, the CEO and CTO are also graduated from the University of Science and Technology, and the University of Science and Technology News can be said to be a brother. However, the speech recognition technology is more derived from the Institute of Automation of the Chinese Academy of Sciences. Its speech recognition technology has certain unique features. In a short period of time, the speech recognition rate even surpassed that of the University of Science and Technology. Therefore, it has also been favored by capital. The B round of financing reached 300 million, mainly targeting the smart home market. But it has been established for more than three years now. It is more publicity, the market development is slower, and the B2B market has not seen improvement. The B2C market rarely hears practical applications. It is estimated that it is still in the stage of burning money.
Go out and ask
Going out to ask questions was established in 2012, and his CEO once worked at Google. After receiving the angel investment from Sequoia Capital and Zhenge Fund, he resigned from Google and founded Shanghai Yu Fanzhi Information Technology Co., Ltd., and determined to build the next generation of mobile voice. Search for products --- "Go out and ask."
The success of going out to ask questions is the ranking of Apple's APP rankings, but I don't know if there are so many built-in maps, so I have to download this software, obviously it is more trouble than finding the map directly. Going out to ask questions also has strong financing ability. In 2015, I got Google's C-round financing, and the accumulated amount of financing has reached 75 million US dollars. Going out to ask questions mainly aimed at the wearable market. Recently, I also launched smart watches and other products, but it is also thunderous and rainy, and I don’t see how the sales of smart watches are.
Other domestic speech recognition companies
The threshold for speech recognition is not high, so major domestic companies have gradually joined in. Sogou began to use Yunzhisheng's speech recognition engine, but soon set up its own speech recognition engine, mainly used in Sogou input method, the effect is also OK.
Of course, Tencent will not fall behind. WeChat has also established its own speech recognition engine, which is used to convert voice into text, but this is still a bit of a gap.
Ali, iQiyi, 360, LeTV, etc. are also building their own speech recognition engines, but these big companies are more self-study, basically technically good, and the industry has no influence.
Of course, in addition to the speech recognition companies in the industry mentioned above, the HTK tools of Cambridge in the academic world have greatly promoted the research in academia, and CMU, SRI, MIT, RWTH, ATR, etc. also promote the development of speech recognition technology.
What is the principle of speech recognition technology?
For speech recognition technology, I believe that everyone has more or less contact and application. We have also introduced the situation of major speech recognition technology companies at home and abroad. But you may still want to know what is the principle of speech recognition technology? Then let's introduce it to everyone.
Speech recognition technology
Speech recognition technology is a technique that allows a machine to transform a speech signal into a corresponding text or command through an identification and understanding process. The purpose of speech recognition is to let the machine give people the auditory characteristics, understand what people say, and make corresponding actions. At present, most speech recognition technologies are based on statistical models. From the perspective of speech generation mechanism, speech recognition can be divided into two parts: speech layer and language layer.
Speech recognition is essentially a process of pattern recognition. The pattern of unknown speech is compared with the reference mode of known speech one by one, and the best matching reference mode is used as the recognition result.
The mainstream algorithms of today's speech recognition technology mainly include dynamic time warping (DTW) algorithm, vector quantization (VQ) method based on nonparametric model, hidden Markov model based on parameter model (HMM), artificial neural network based on artificial neural network. Speech recognition methods such as (ANN) and support vector machines.
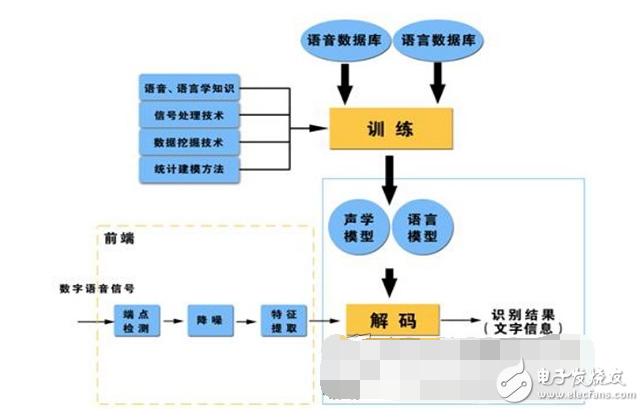
Basic block diagram of speech recognition
Speech recognition classification :According to the degree of dependence on the speaker, it is divided into:
(1) Specific person speech recognition (SD): Only the voice of a specific user can be recognized, training → use.
(2) Non-specific person speech recognition (SI): recognizes the voice of any person without training.
According to the requirements of the way of speaking, it is divided into:
(1) Isolated word recognition: Only a single word can be recognized at a time.
(2) Continuous speech recognition: When the user speaks at a normal speech rate, the sentence can be recognized.
Speech recognition system
The model of the speech recognition system usually consists of two parts: the acoustic model and the language model, which correspond to the calculation of the speech-to-syllable probability and the calculation of the syllable-to-word probability.
Sphinx is a large vocabulary, non-specific, continuous English speech recognition system developed by Carnegie Mellon University. A continuous speech recognition system can be roughly divided into four parts: feature extraction, acoustic model training, language model training, and decoder.
(1) Preprocessing module
The input original speech signal is processed, the unimportant information and background noise are filtered out, and the endpoint detection of the speech signal (finding the beginning and end of the speech signal) and the speech framing are performed (approximately within 10-30 ms) The speech signal is processed for a short period of time, dividing the speech signal into segments for analysis, and pre-emphasis (boosting the high-frequency portion).
(2) Feature extraction
The redundant information in the speech signal that is useless for speech recognition is removed, and information that reflects the essential characteristics of the speech is retained and expressed in a certain form. That is to say, the key feature parameters reflecting the characteristics of the speech signal are extracted to form a feature vector sequence for subsequent processing.
At present, there are many methods for extracting features that are more commonly used, but these extraction methods are derived from the spectrum.
(3) Acoustic model training
The acoustic model parameters are trained according to the characteristic parameters of the training speech library. When identifying, the characteristic parameters of the speech to be recognized can be matched with the acoustic model to obtain a recognition result.
At present, the mainstream speech recognition system mostly uses the hidden Markov model HMM to model the acoustic model.
(4) Language model training
The language model is a probability model used to calculate the probability of a sentence appearing. It is mainly used to determine which word sequence is more likely, or to predict the content of the next upcoming word in the presence of a few words. To put it another way, the language model is used to constrain word search. It defines which words can follow the last recognized word (the match is a sequential process), which eliminates some impossible words for the matching process.
Language modeling can effectively combine the knowledge of Chinese grammar and semantics, and describe the intrinsic relationship between words, thereby improving the recognition rate and reducing the search range. The language model is divided into three levels: dictionary knowledge, grammar knowledge, and syntactic knowledge.
The training text database is grammatically and semantically analyzed, and the language model is obtained through training based on statistical models. The language modeling methods mainly include two methods based on the rule model and the statistical model.
(5) Speech decoding and search algorithm
Decoder: Refers to the recognition process in speech technology. For the input speech signal, an identification network is established according to the trained HMM acoustic model, language model and dictionary, and the best path is found in the network according to the search algorithm, and the path is capable of outputting the speech signal with maximum probability. The word string, so that the text contained in the speech sample is determined. Therefore, the decoding operation refers to the search algorithm: it refers to the method of finding the optimal word string through the search technology at the decoding end.
The search in continuous speech recognition is to find a sequence of word models to describe the input speech signal, thereby obtaining a sequence of word decoding. The search is based on scoring the acoustic model scores in the formula and the language model. In actual use, it is often necessary to add a high weight to the language model based on experience and set a long word penalty score. Today's mainstream decoding techniques are based on the Viterbi search algorithm, as well as Sphinx.
Difficulties in speech recognition technologySpeaker difference
Different speakers: pronunciation organ, accent, speaking style
Same speaker: different time, different status
Noise effect
Background noise
Transmission channel, microphone frequency response
Robust technology
Discriminative training
Feature compensation and model compensation
Specific application of speech recognition
Command word system
The recognition grammar network is relatively limited, and the requirements for users are stricter.
Menu navigation, voice dialing, car navigation, alphanumeric recognition, etc.
Intelligent interactive system
The requirements for users are more relaxed, and the combination of identification and other fields of technology is needed.
Call routing, POI voice fuzzy query, keyword detection
Large vocabulary continuous speech recognition system
Massive entry, wide coverage, guaranteed correct rate and poor real-time performance
Audio transfer
Voice search combined with the Internet
Implement speech-to-text, speech-to-speech search
LCD Tonch Screen For Iphone 12
Lcd Tonch Screen For Iphone 12,Lcd Touch Screen For Iphone X12Pro,Lcd Display For Iphone X12Pro,Mobile Lcd For Iphone X12Pro
Shenzhen Xiangying touch photoelectric co., ltd. , https://www.starstp.com